Week 10 and 11
27th July - 9th August , 2020.
On Monday, the 27th of July, I had two off-policy algorithms, which were almost complete in implementation, but both were not able to converge.
These two weeks were challenging, as I had to spend a large chunk of time just looking at the code, comparing parameters and rerunning with minor parameter changes, which btw is not at all satisfying, especially if you cannot find the bug in the end. It may lead to self-doubt at times :(
But I was lucky enough to find some minor faults in both of these algorithms during the first week itself, and seeing the avg reward go up just made my day! :D
Important changes:
- Finally!!! The categorical dqn PR is merged. This PR was almost ready till the 2nd week of June. But due to the test not passing, I thought that maybe there’s a bug somewhere. So the rest of the time I spent on finding that bug, by comparing and observing each step and parameter carefully. Well, turns out the implementation was correct, but the mlpack’s implementation of
CartPole-v0itself had a slightly different reward function, caused the implementation to fail miserably.
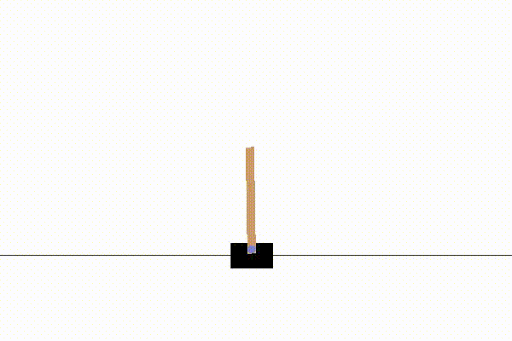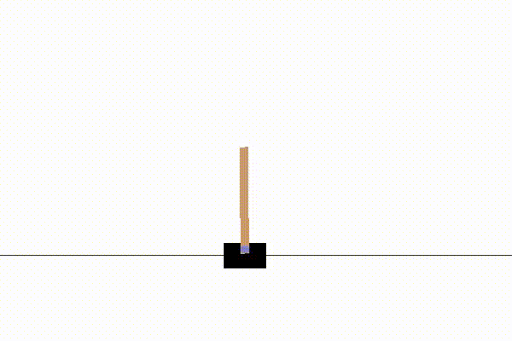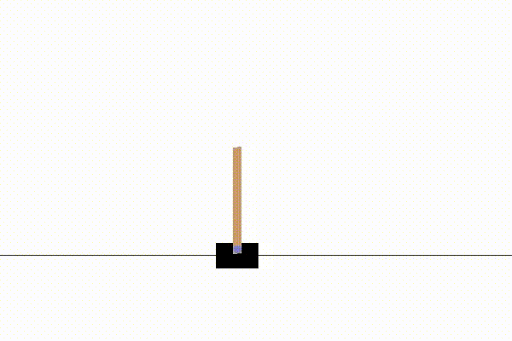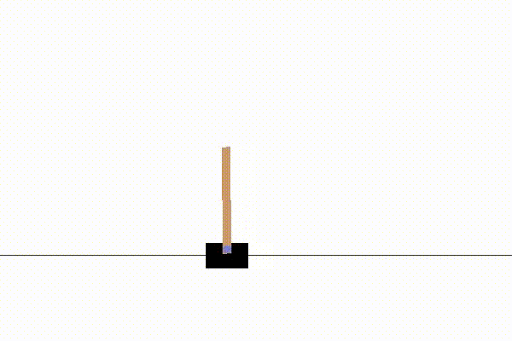
Anyway, the end result was a solved CartPole example, which was what we needed.
- Added two new solved environments as examples to the mlpack/examples repo.


Interestingly, the Pendulum environment is a continuous action space environment, but DQN was used to train the agent. This was done by “discretizing” the env’s action space.
Please have a look at the pendulum notebook for more details.
- Soft Actor-Critic is ready to be merged. Two major notorious bugs 🐛🐛 were found and successfully removed!
If everything goes well, SAC should become the first RL algo added to mlpack, that can solve a continuous action-space environment properly.
Problems faced:
As mentioned above, the Categorical DQN had no bugs in it’s implementation, but pointing out the small bug in the environment took up a lot of time!
As for SAC, there were two major flaws I noticed and removed:
-
After doing some math, I finally understood that instead of passing the gradient-wrt-the-input into the policy network during backward pass, I was passing the gradient-wrt-weights.
-
With the above problem solved, I thought the agent should converge now. Turns out, the line
arma::rowvec nextQ = sampledRewards + config.Discount() * (1 - isTerminal) % Q1should be written with brackets like this:arma::rowvec nextQ = sampledRewards + config.Discount() * ((1 - isTerminal) % Q1). The funny part is, if u replaceconfig.Discount()with adiscount, wheredouble discount = config.Discount();, then it doesn’t matter if you keep the brackets or not. I guess I was lucky to find this notorious bug 🐛!!
Some other flaws were also rectified. Please find the discussion here.
Suggestions:
Two songs at the top of my playlist this week:

Jason Mraz's Have it All
and

Sound of silence by Disturbed
Thanks for reading, and have a good one ;)